

How To Do Data Quality Checks Using Apache Spark Dataframes
Automated Data Quality Testing at Calibration using Apache Spark
With An Open Source library from Amazon — Deequ
I have been working equally a Technology Builder, mainly responsible for the Information Lake/Hub/Platform kind of projects. Every solar day we ingest data from 100+ concern systems so that the data can exist made available to the analytics and BI teams for their projects.
Trouble Statement
While ingesting information, nosotros avoid any transformations. The data is replicated every bit it is from the source. The sources can be of type MySQL, SQL Server, Oracle, DB2, etc. The target systems tin can exist Hadoop/Hive or Big Query. Even though at that place is no transformation done on the information since the source and target systems are unlike, sometimes these simple information ingestions could cause data quality issues. Source and target systems can have different information types which might cause more issues. Special characters in data might cause row/cavalcade shiftings.
Possible Solution
In order to solve this trouble, nearly of the developers use a transmission approach for information quality testing after they built the information pipelines. This can be done past running some elementary tests like
- Sample data comparing between source and target
- Null checks on main key columns
- Null checks on engagement columns
- Count comparison for the categorical columns
- etc.
This approach sometimes works well merely it is fourth dimension-consuming and fault-prone. Hence I started looking for some automated options.
Deequ at Amazon
My search for an open-source data quality testing framework stopped at Deequ library from Amazon. Deequ is beingness used at Amazon for verifying the quality of many large production datasets. The system keeps on computing data quality metrics on a regular basis.

Deequ is built on tiptop of Apache Spark hence it is naturally scalable for the huge amount of data. The all-time part is, you don't need to know Spark in particular to use this library. Deequ provides features like —
- Constraint Suggestions — What to test. Sometimes it might exist difficult to discover what to test for in a particular object. Deequ provides congenital-in functionality to identify constraints to be tested.
- Metrics Computation — Once we know what to test, nosotros can use the suggestion given by the library and run the tests to compute the metrics.
- Constraint Verification — Using Deequ, we can also put test cases and get results to be used for the reporting.
Let's get into action
In order to run Deequ, nosotros demand to first prepare our workstation. You lot tin try this out on a simple Windows/Linux/Mac motorcar.
Pre-requisites
- Install Scala — You lot tin can download and install Scala from — https://www.scala-lang.org/
- Install Apache Spark — You tin download and install Spark from — https://spark.apache.org/
- Download Deequ library — You can download the Deequ JAR as shown beneath —
wget http://repo1.maven.org/maven2/com/amazon/deequ/deequ/1.0.1/deequ-1.0.ane.jar - Set up the data to be tested — If you don't have any data to be tested, you can prepare one. For this tutorial, I accept a MySQL instance installed and I take loaded some sample information from — http://www.mysqltutorial.org/mysql-sample-database.aspx
- Download JDBC Jars — For whichever type of database y'all want to run these tests, please make sure to add JDBC jars in
$SPARK_HOME/jars. Since I am going to run my tests on MySQL & Hive, I have added respective JDBC jars.
Starting time Spark in interactive mode
In order to run tests, we will start Spark in interactive style using the library downloaded in the previous step every bit shown below —
PS D:\work\DataTesting> spark-shell --conf spark.jars=deequ-1.0.ane.jar
Spark context Spider web UI available at http://localhost:4040
Spark context available as 'sc' (main = local[*], app id = local-1561783362821).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version two.4.3
/_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to accept them evaluated.
Type :aid for more than information. scala>
Constraint Suggestions
I am planning to run tests on client table loaded in the earlier steps. You tin can use MySQL Workbench/CLI to verify the data is loaded properly.
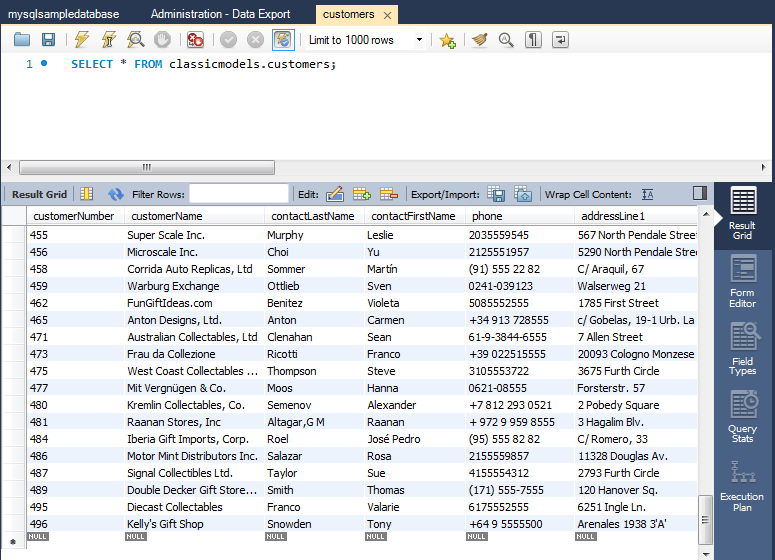
In lodge to run constraint suggestions, we need to start connect to the DB using Spark.
Please make a note, with this approach, we are doing a query push button downwards to the underlying databases. And then please be careful while running on production systems direct.
import org.apache.spark.sql.SQLContext val sqlcontext = new org.apache.spark.sql.SQLContext(sc) val datasource = sqlcontext.read.format("jdbc").option("url", "jdbc:mysql://<IP>:3306/classicmodels").option("commuter", "com.mysql.jdbc.Commuter").option("dbtable", "customers").option("user", "<username>").pick("password", "<password>").option("useSSL", "fake").load()
On a valid connection, y'all can bank check the schema of the table —
scala> datasource.printSchema()
root
|-- customerNumber: integer (nullable = true)
|-- customerName: string (nullable = true)
|-- contactLastName: cord (nullable = true)
|-- contactFirstName: string (nullable = true)
|-- phone: string (nullable = truthful)
|-- addressLine1: string (nullable = true)
|-- addressLine2: cord (nullable = true)
|-- city: string (nullable = truthful)
|-- state: string (nullable = true)
|-- postalCode: cord (nullable = truthful)
|-- country: string (nullable = true)
|-- salesRepEmployeeNumber: integer (nullable = truthful)
|-- creditLimit: decimal(10,2) (nullable = true) scala>
Now, permit's run the constraint suggestions —
import com.amazon.deequ.suggestions.{ConstraintSuggestionRunner, Rules}
import spark.implicits._ // for toDS method // We ask deequ to compute constraint suggestions for the states on the data
val suggestionResult = { ConstraintSuggestionRunner()
// data to suggest constraints for
.onData(datasource)
// default ready of rules for constraint proposition
.addConstraintRules(Rules.DEFAULT)
// run data profiling and constraint suggestion
.run()
} // We can now investigate the constraints that Deequ suggested.
val suggestionDataFrame = suggestionResult.constraintSuggestions.flatMap {
case (column, suggestions) =>
suggestions.map { constraint =>
(column, constraint.description, constraint.codeForConstraint)
}
}.toSeq.toDS()
Once the execution is complete, you tin print the suggestions as shown beneath —
scala> suggestionDataFrame.toJSON.collect.foreach(println) {"_1":"addressLine1","_2":"'addressLine1' is not zero","_3":".isComplete(\"addressLine1\")"}
{"_1":"city","_2":"'city' is non nix","_3":".isComplete(\"city\")"}
{"_1":"contactFirstName","_2":"'contactFirstName' is not null","_3":".isComplete(\"contactFirstName\")"}
{"_1":"land","_2":"'state' has less than 69% missing values","_3":".hasCompleteness(\"land\", _ >= 0.31, Some(\"It sho
uld be above 0.31!\"))"}
{"_1":"salesRepEmployeeNumber","_2":"'salesRepEmployeeNumber' has less than 25% missing values","_3":".hasCompleteness(\
"salesRepEmployeeNumber\", _ >= 0.75, Some(\"It should be above 0.75!\"))"}
{"_1":"salesRepEmployeeNumber","_2":"'salesRepEmployeeNumber' has no negative values","_3":".isNonNegative(\"salesRepEmp
loyeeNumber\")"}
{"_1":"customerName","_2":"'customerName' is not null","_3":".isComplete(\"customerName\")"}
{"_1":"creditLimit","_2":"'creditLimit' is not null","_3":".isComplete(\"creditLimit\")"}
{"_1":"creditLimit","_2":"'creditLimit' has no negative values","_3":".isNonNegative(\"creditLimit\")"}
{"_1":"country","_2":"'state' is not zippo","_3":".isComplete(\"country\")"}
{"_1":"state","_2":"'country' has value range 'Usa', 'Germany', 'France', 'Spain', 'UK', 'Australia', 'Italy', 'New Ze
aland', 'Switzerland', 'Singapore', 'Finland', 'Canada', 'Portugal', 'Republic of ireland', 'Norway ', 'Republic of austria', 'Sweden', 'Belgiu
yard' for at least 84.0% of values","_3":".isContainedIn(\"country\", Array(\"United states\", \"Germany\", \"France\", \"Spain\", \"
U.k.\", \"Commonwealth of australia\", \"Italy\", \"New Zealand\", \"Switzerland\", \"Singapore\", \"Finland\", \"Canada\", \"Portugal\",
\"Republic of ireland\", \"Norway \", \"Austria\", \"Sweden\", \"Belgium\"), _ >= 0.84, Some(\"Information technology should be above 0.84!\"))"}
{"_1":"postalCode","_2":"'postalCode' has less than nine% missing values","_3":".hasCompleteness(\"postalCode\", _ >= 0.9,
Some(\"It should be above 0.9!\"))"}
{"_1":"customerNumber","_2":"'customerNumber' is not goose egg","_3":".isComplete(\"customerNumber\")"}
{"_1":"customerNumber","_2":"'customerNumber' has no negative values","_3":".isNonNegative(\"customerNumber\")"}
{"_1":"contactLastName","_2":"'contactLastName' is not null","_3":".isComplete(\"contactLastName\")"}
{"_1":"telephone","_2":"'phone' is not null","_3":".isComplete(\"phone\")"}
This means your exam cases are fix. Now let's run the metrics computation.
Metrics Computation
Looking at the columns and suggestions, now I want to run the metrics computations. Hither is how yous can practise and so —
import com.amazon.deequ.analyzers.runners.{AnalysisRunner, AnalyzerContext}
import com.amazon.deequ.analyzers.runners.AnalyzerContext.successMetricsAsDataFrame
import com.amazon.deequ.analyzers.{Compliance, Correlation, Size, Completeness, Hateful, ApproxCountDistinct, Maximum, Minimum, Entropy, GroupingAnalyzer} val analysisResult: AnalyzerContext = { AnalysisRunner
// data to run the analysis on
.onData(datasource)
// define analyzers that compute metrics
.addAnalyzer(Size())
.addAnalyzer(Completeness("customerNumber"))
.addAnalyzer(ApproxCountDistinct("customerNumber"))
.addAnalyzer(Minimum("creditLimit"))
.addAnalyzer(Mean("creditLimit"))
.addAnalyzer(Maximum("creditLimit"))
.addAnalyzer(Entropy("creditLimit"))
.run()
}
On a successful run, you can see the results
// retrieve successfully computed metrics every bit a Spark data frame
val metrics = successMetricsAsDataFrame(spark, analysisResult) metrics.testify() scala> metrics.show()
+-------+--------------+-------------------+-----------------+
| entity| case| name| value|
+-------+--------------+-------------------+-----------------+
| Cavalcade| creditLimit| Entropy|iv.106362796873961|
| Column|customerNumber| Completeness| i.0|
| Column|customerNumber|ApproxCountDistinct| 119.0|
| Column| creditLimit| Minimum| 0.0|
| Column| creditLimit| Mean|67659.01639344262|
| Cavalcade| creditLimit| Maximum| 227600.0|
|Dataset| *| Size| 122.0|
+-------+--------------+-------------------+-----------------+
You tin also store these numbers for further verifications or to even evidence trends. In this case, nosotros are running ApproxCountDistinct, this is calculated using the HyperLogLog algorithm. This reduces the burden on the source organization by approximating the distinct count.
A full list of bachelor Analyzers can be found at — https://github.com/awslabs/deequ/tree/master/src/main/scala/com/amazon/deequ/analyzers
Constraint Verification
At present permit's run test cases using the verification suites.
import com.amazon.deequ.{VerificationSuite, VerificationResult}
import com.amazon.deequ.VerificationResult.checkResultsAsDataFrame
import com.amazon.deequ.checks.{Check, CheckLevel} val verificationResult: VerificationResult = { VerificationSuite()
// information to run the verification on
.onData(datasource)
// define a data quality check
.addCheck(
Check(CheckLevel.Error, "Information Validation Check")
.hasSize(_ == 122 )
.isComplete("customerNumber") // should never be Zip
.isUnique("customerNumber") // should not contain duplicates
.isNonNegative("creditLimit")) // should non contain negative values
// compute metrics and verify check weather condition
.run()
}
Once the run is complete, you can look at the results
// convert check results to a Spark data frame
val resultDataFrame = checkResultsAsDataFrame(spark, verificationResult) resultDataFrame.testify() scala> resultDataFrame.show()
+-------------------+-----------+------------+--------------------+-----------------+------------------+
| check|check_level|check_status| constraint|constraint_status|constraint_message|
+-------------------+-----------+------------+--------------------+-----------------+------------------+
|Information Validate Check| Mistake| Success|SizeConstraint(Si...| Success| |
|Information Validate Check| Mistake| Success|CompletenessConst...| Success| |
|Data Validate Check| Fault| Success|UniquenessConstra...| Success| |
|Information Validate Cheque| Mistake| Success|ComplianceConstra...| Success| |
+-------------------+-----------+------------+--------------------+-----------------+------------------+
If a detail case is failed, you can accept a look at the details equally shown below
resultDataFrame.filter(resultDataFrame("constraint_status")==="Failure").toJSON.collect.foreach(println) Data Validation on Incremental Information
Deequ besides provides a way to validate incremental data loads. Yous can read more about this arroyo at — https://github.com/awslabs/deequ/hulk/master/src/master/scala/com/amazon/deequ/examples/algebraic_states_example.dr.
Anomaly Detection
Deequ as well provided an arroyo to detect anomalies. The GitHub folio lists down some approaches and strategies. Details can be establish here — https://github.com/awslabs/deequ/tree/master/src/primary/scala/com/amazon/deequ/anomalydetection
Conclusion
Overall, I see Deequ equally a great tool to be used for data validation and quality testing in Data Lakes/ Hub/Data Warehouse kind of use cases. Amazon has even published a research paper nearly this approach. This can be viewed at — http://www.vldb.org/pvldb/vol11/p1781-schelter.pdf
If yous endeavour this out, do let me know your experience. If yous have some interesting ideas to accept this further, please don't forget to mention those in the comments.
Hey, if you enjoyed this story, bank check out Medium Membership! But $five/month! Your membership fee directly supports me and other writers you read. You'll besides get full access to every story on Medium.

How To Do Data Quality Checks Using Apache Spark Dataframes,
Source: https://towardsdatascience.com/automated-data-quality-testing-at-scale-using-apache-spark-93bb1e2c5cd0
Posted by: mcclurgyoughat.blogspot.com
0 Response to "How To Do Data Quality Checks Using Apache Spark Dataframes"
Post a Comment